Model training
Once all data has been collected and the pre-processor is built, data needs to be passed to the model for training. Before the model can be trained the layers of a model must be configured. Imagimob gives users an Auto ML wizard which can generate multiple different models to be trained and compared to find the best fitting model for a given use case. IMAGIMOB Studio also allows for users to select their own model layers and configure each layer individually allowing for a wide range of expertise.
Supported layers (MTB-ML)
If using the MTB-ML deployment flow, it is important to note that Imagimob and MTB-ML do not support all the same layers. If a model is generated with layers that are not supported by MTB-ML, then an error is produced when trying to generate source for the model in the MTB-ML configurator. The Imagimob deployment flow generates model source code with IMAGIMOB Studio, which means all layers all supported. The table below lists the supported model layers and flow layers:
| Flow | Supported model layers |
|---|---|
| MTB-ML | Activation / Add / AveragePooling1D / AveragePooling2D / BatchNormalization / Clipped RELU / Concatenate / Conv1D / Conv2D / Dense / DepthwiseConv2D / Dropout / Flatten / GlobalAveragePolling1D / GlobalAveragePooling2D / GlobalMaxPooling1D / GlobalMaxPooling2D / InputLayer / LeakyReLU / MaxPooling1D / MaxPooling2D / ReLU / Reshape / SeparableConv2D / Softmax / Transpose / Upsampling |
| Imagimob | Activation / AveragePooling1D / AveragePooling2D / BatchNormalization / Convolution1DTranspose / Conv1D / Conv2D / Dense / Dropout / Flatten / GlobalAveragePooling1D / GlobalAveragePooling2D / GlobalMaxPooling1D / GatedRecurrentUnit/ InputLayer / LeakyRelu / LSTM / MaxPooling1D / MaxPooling2D / Rescaling / Reshape / TimeDistributed |
Auto ML model wizard
IMAGIMOB Studio’s Auto ML wizard allows for the creation of multiple model architectures that are then trained and compared to find the best performing model. The Auto ML wizard can be configured for different model families, classifiers, sizes, and learning rate. The wizard then generates models based on the configuration. This speeds up the model development phase by prioritizing the main features of a model.
For the Human Activity Recognition and Baby Crying Detection starter projects, multiple models with different architectures are included in the project.
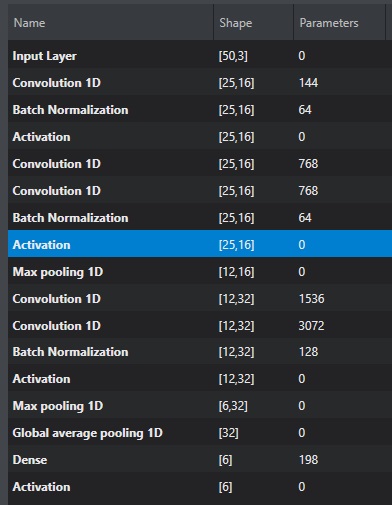
Model architecture for Human Activity Recognition
The Human Activity Recognition model is a standard convolutional neural network (CNN) model consisting of five convolutional groups. These groups are divided into three groups of convolutional blocks (one or two layers), a batch normalization layer, a max pooling layer, and a dense layer at the end acts as a classifier. The complete model architecture is shown in the image.
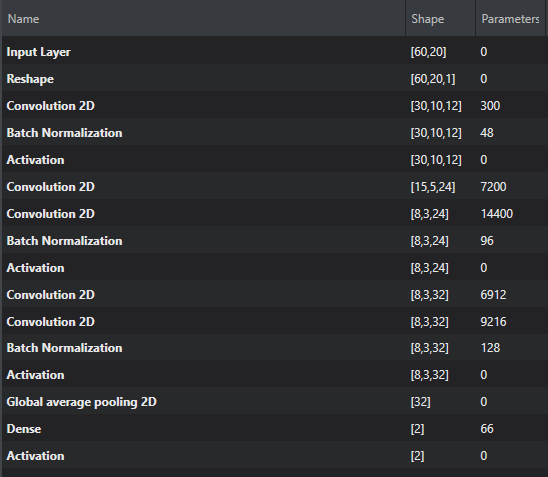
Model architecture for Baby Crying Detection
The Baby Crying Detection model is a standard 2D convolutional neural network (CNN) model consisting of five convolutional groups. These groups are divided into three groups of convolutional blocks (one or two layers), a batch normalization layer, a rectified linear unit (ReLU) activation layer, and an average pooling layer. The complete model architecture can be seen in the image.
The pre-defined models can be trained with the newly imported and labeled data by skipping to Model training and results.
To generate a model:
-
Navigate to your project directory and double-click the project file (.improj).
-
Click on the Training tab on the left pane.
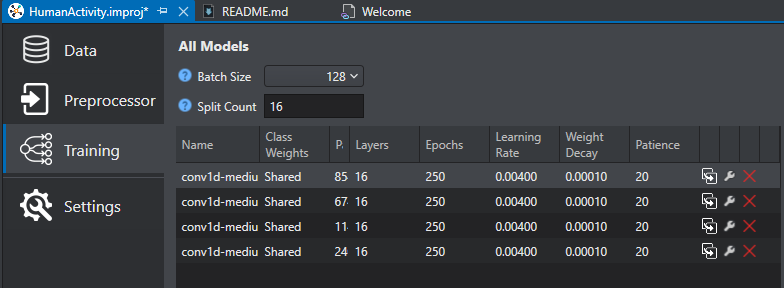
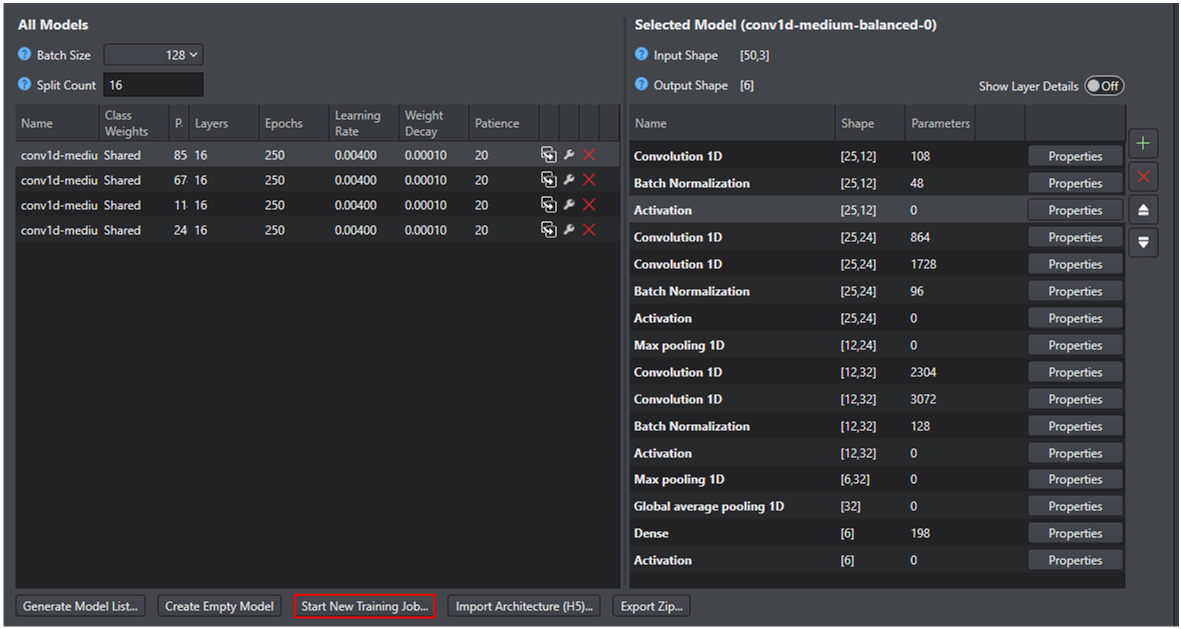
This image shows the Human Activity Recognition project which includes defined models. In an empty project this will show no models.
-
Open the Auto ML wizard by selecting the Generate Model List.
-
The Auto ML wizard will appear with the following configurable parameters.
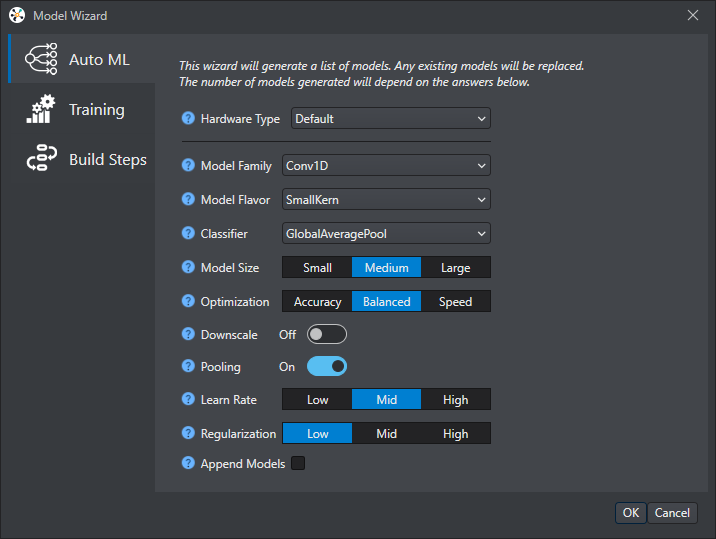
The table below lists the Auto ML configurable parameters:
Parameter Options MTB-ML flow Hardware Type Default, Syntiant Default Model Family Conv1D, Conv1DLSTM, Conv2D Conv1D, Conv2D Model Flavor SmallKern, LargeKern Application dependent: SmallKern – Quicker Inference time, LargerKern – Higher Accuracy Classifier GlobalAveragePool, Hybrid, Dense GlobalAveragePool, Dense Model Size Small, Medium, Large Application dependent: Dependent on how much flash the MCU has available. Larger models tend to have a higher accuracy. Optimization Accuracy, Balanced, Speed Application dependent: Does the application require high accuracy or quick inference time Downscale On, Off Application dependent: When turned on, increases model speed and accuracy when the model identifies large features in the input data, otherwise the accuracy can drop Pooling On, Off Recommended: On - increases speed, lowers memory cost, with minor impact to accuracy Learn Rate Low, Mid, High Recommended: Mid Regularization Low, Mid, High Used to reduce over-fitting to the training data -
IMAGIMOB Studio offers hyperparameter tuning, these are options such as number of epochs, batch size, and loss function selection. For more information, see Generating model.
-
Select OK and the model list is generated.
Layer configuration
All models generated by the Auto ML wizard can be changed layer by layer. This allows for fine tuning of the models for more advanced users. The adding, removing, and configuring of model layers works like the pre-processing step.
-
Select one of the models generated by the Auto ML model wizard. This brings up the model architecture.
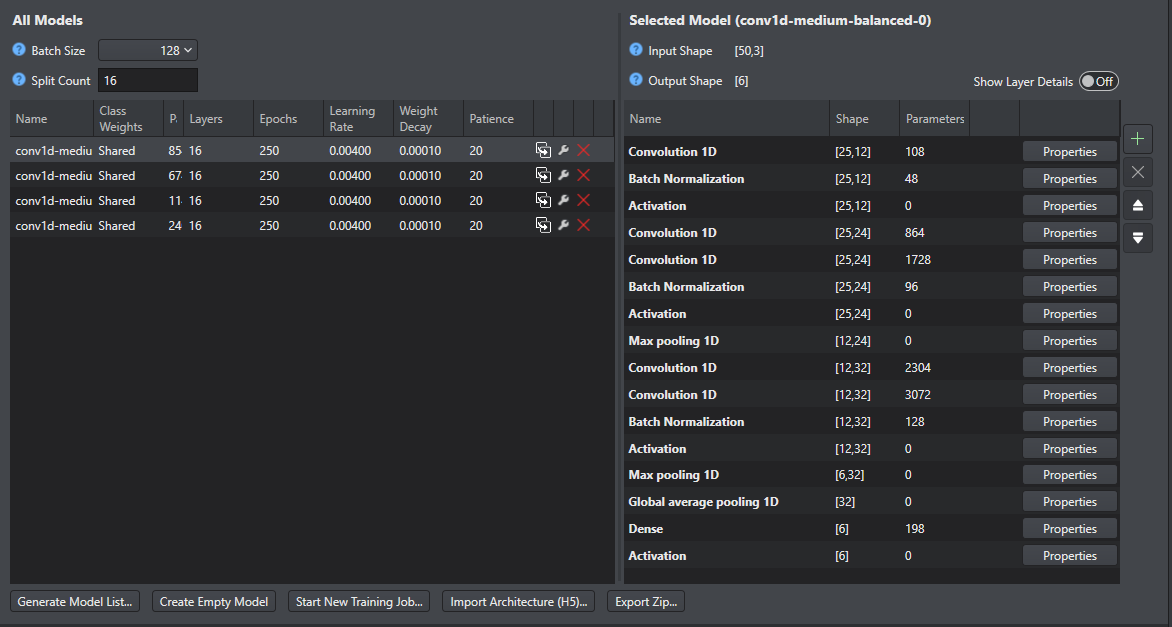
-
Each of these layers can be removed by selecting the layer and pressing the delete button (X) or configured by pressing the Properties button.
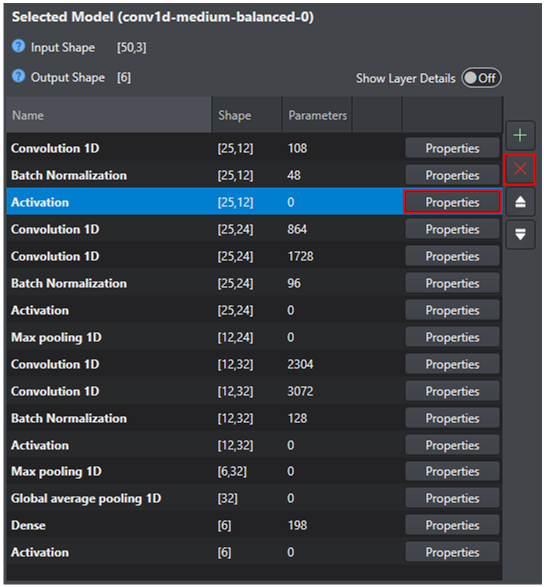
-
A layer can be added to the model by pressing the plus (+) button. This will bring up the Add New Layer window where any supported layer can be configured and added to the model.
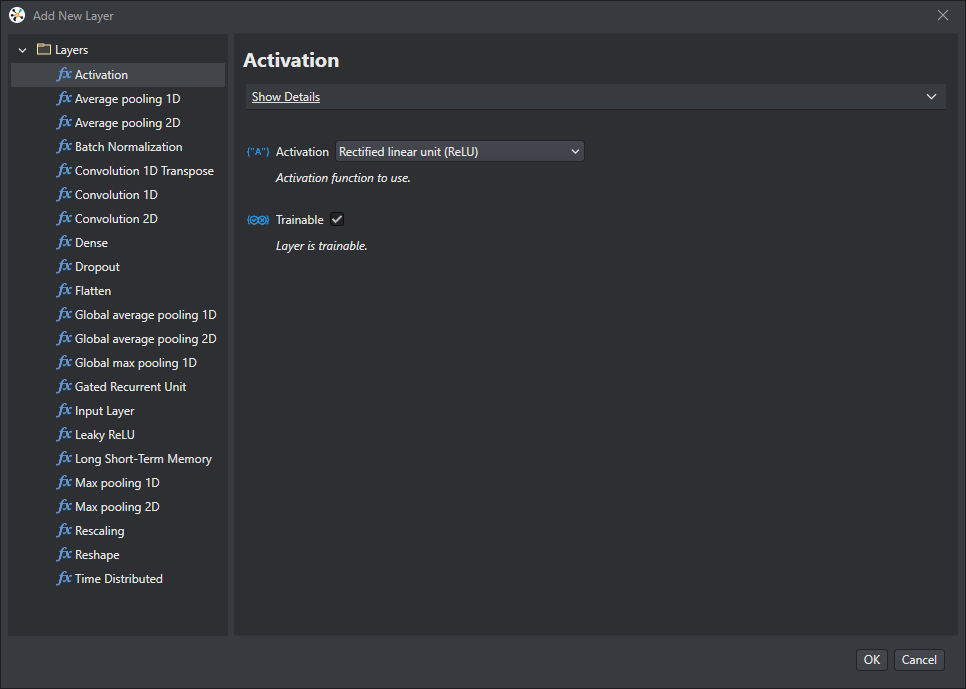
Model training and results
IMAGIMOB Studio offers many different training statistics and metrics to analyze the strengths and weakness of a model. The statistics include accuracy of validation and test data as well as confusion matrix to see what classifications performed well.
To start training and review the training statistics:
-
Start the model training by selecting Start New Training Job.
-
A prompt directs to the Imagimob account sign-in to start the training.
-
A New Training Job window will come up showing the user their available credits and a Description window to add comments about the training job. Select OK to start the training job.
-
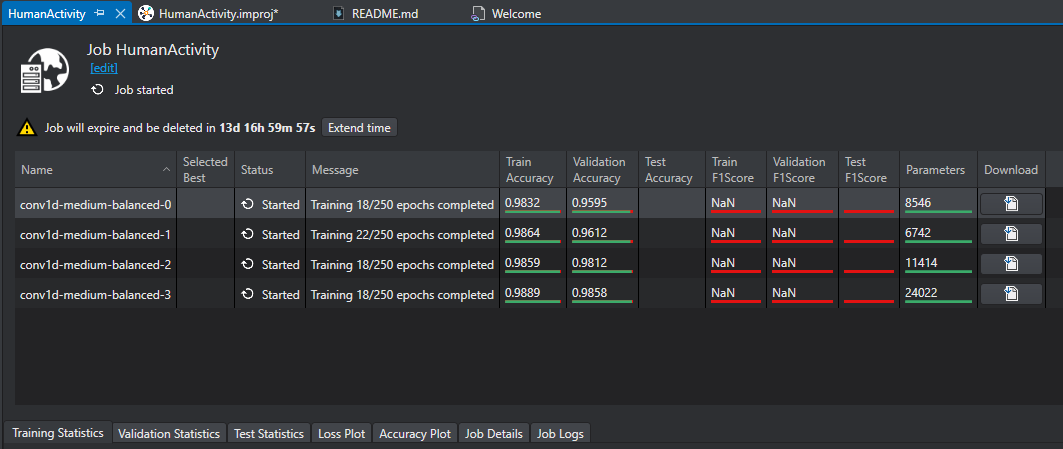
Once a training job is started a window will come up asking if the user wants to open the current job, select Yes and the following screen shows up giving stats on the training progress.
-
Once the Status for each model has changed from Started to Completed the model’s results can be validated. Select one of the models and the training statistics for that model.
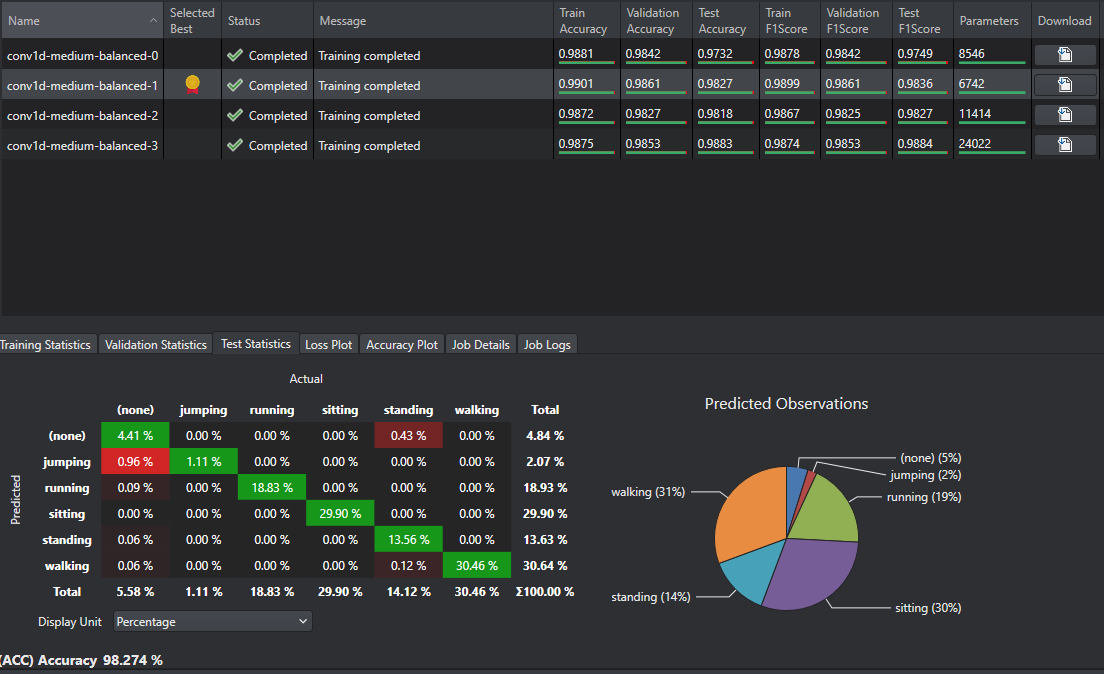
Here users can see the overall accuracy of the model and a confusion matrix for training, validation, and test data. The confusion matrix shows when data was misclassified and may mean that the model layers need to be changed or that more training data needs to be added. For this particular model, jumping was classified as none at a high rate while jumping only made up 2 percent of the predicted observations. This means that more jumping data should be collected for training data to increase the model accuracy.
-
IMAGIMOB Studio compares the model statistics and recommends the best model by putting a star in the Selected Best category.
-
Model development is a reiterative process and if a model does not perform as needed this may mean that more training data needs to be added, the pre-processor needs re-configuring, or the model layers should be changed.
-
When a model meets the user’s criteria the model can be downloaded using the download icon next to the model and the Download Model Files comes up. Select Download and pick the Model folder in the Imagimob project, then select OK.

The model is now downloaded in the Model directory of the project.
After training the machine learning model, the next step is to deploy the model. To know how to deploy the model, refer to Deployment.