Pre-processing
The second main step in producing a model is pre-processing. This is all the processing done on the collected data before using it to train a model and to run the inference engine.
All data that is going to be passed into the model needs to be processed. Doing this can give a model better accuracy without changing the architecture of the model. Imagimob offers a wide variety of pre-processing layers that can easily be added and configured into your pipeline and later deployed onto an embedded device.
Pre-processing configuration
IMAGIMOB Studio allows users to introduce pre-processing into the pipeline using the Preprocessor tab after selecting the *.improj file. Imagimob supports adding many different processing layers that will be used before training the model and can also be exported into C code for an embedded device.
For the Human Activity Recognition and Baby Crying Detection starter projects, the pre-processing layers are already added.
Pre-processing layers for Human Activity Recognition
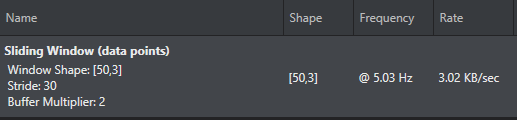
The Human Activity Recognition project uses a “Sliding Window” for the pre-processing. The sliding window means that each data set that is fed to the model or inference engine overlaps with the previous sample. This makes sure that a pattern that the model is looking for is not broken up between two different data sets. The preprocessor is fed an input shape of 3 for the three values of the IMU (Accel_x, Accel_y, Accel_z). The output is a [50, 3] buffer that can then be fed to the inference engine at a rate of 3 Hz. With a 50 Hz IMU sample frequency this means the model is evaluating over a period of 1 second. The sliding window is configured as shown in the image.
Pre-processing layers for Baby Crying Detection
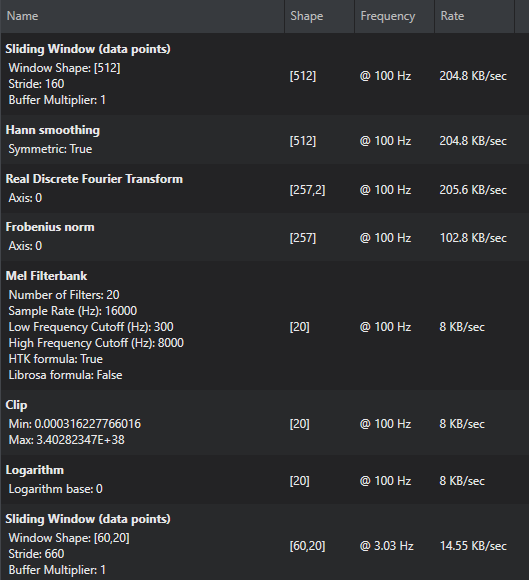
The Baby Crying Detection pre-processor is fed one PDM sample at a time at a frequency of 16 kHz. The pre-processor used in this starter project generates a Mel spectrogram of the input audio data. Such a spectrogram is obtained by (1) calculating the Fast Fourier Transform (FFT) of a window of raw audio data and (2) by applying a Mel filter bank to it. This is a commonly used technique in audio pre-processing, and it helps the model in focusing on the relevant features of the audio signal thereby reducing the amount of data that the model needs to process. A sliding window is used to input the spectrogram data to the actual neural network. The output is a [60, 20] buffer that can be produced at 3 Hz. The complete pre-processing configuration can be seen in the image.
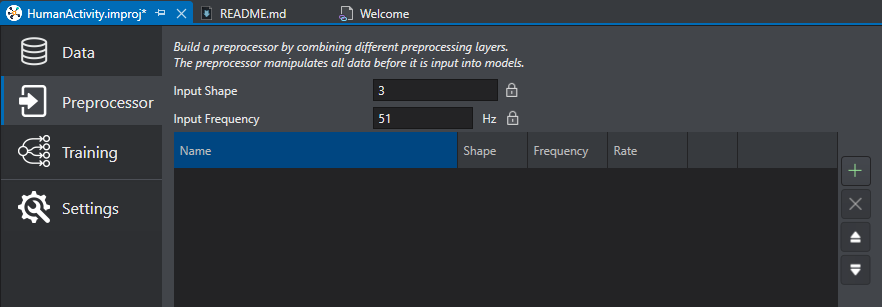
At the top of the Preprocessor tab are two locked variables called Input Shape and Input Frequency. These are auto generated based on the imported data.
Configure the pr-eprocessor
To create a pre-processing pipeline:
-
Select the Preprocessor tab.
-
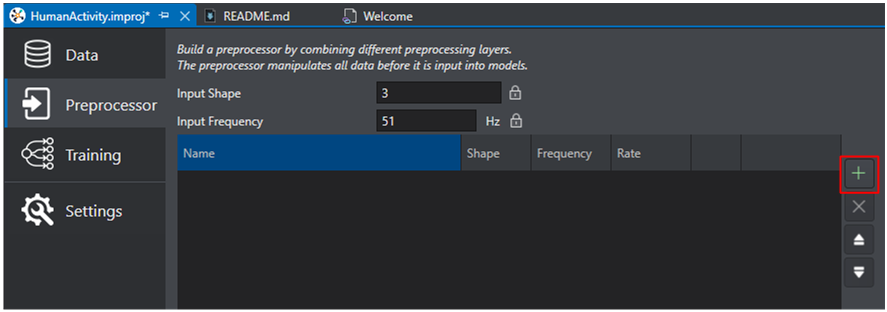
To add a layer into the pipeline, click the plus icon on the right.
-
A list of supported pre-processing layers shows up that can be configured and added to the pipeline.
-
Select the pre-processing layer required. Configure it based on the data being used and select OK to bring the layer into the pipeline.
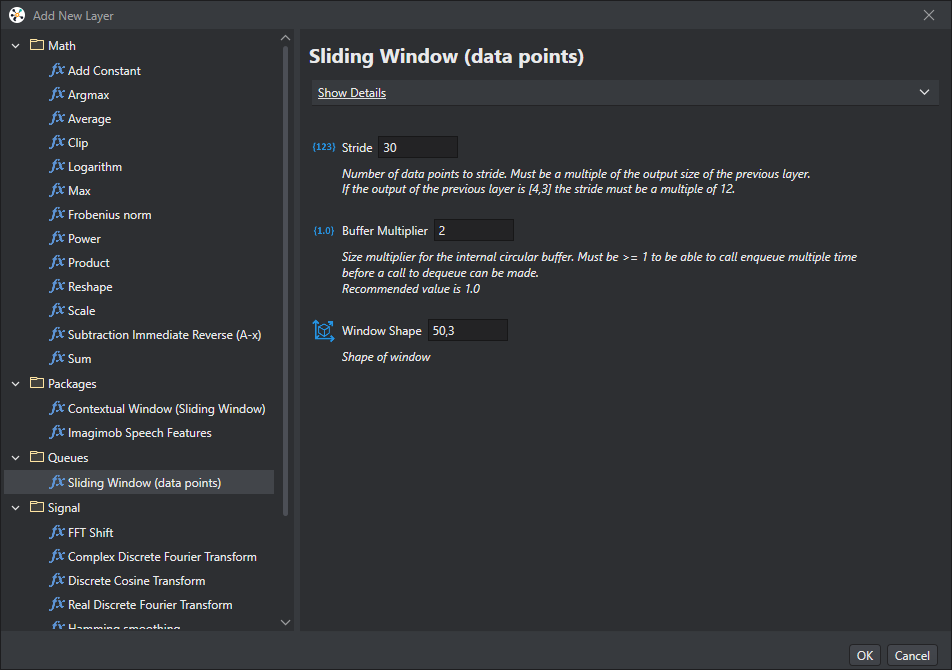
The sliding window for the Human Activity recognition starter code is shown in the figure. This pre-processor shifts data by 30 data points (10 x, y, z samples), can store two complete data sets, and is configured to produce a window shape of 50 by 3.
-
The pre-processor gives information for the output shape, the frequency at which data will be ready, and the data rate.
-
Steps 2 through 4 can be repeated to build multiple layers in a pipeline which can be seen in the Pre-processing layers for Baby Crying Detection.
For more information on setting up a pre-processing pipeline, see Preprocessing.
After configuring the pre-processor, the next step is to train the model. To know how to train the model, refer to Model training.