Data Distribution
After you add data to the project, you need to distribute the data into different datasets. You can split the data into the following three sets:
-
Train Set : Data in the train set is used to train the model
-
Validation Set : Data in the validation set is used to test and evaluate the performance of the model during training
-
Test Set : Data in the test set is used at the end of training to evaluate the performance of the model on unseen data
It is recommended to keep the training set significantly bigger than the validation and test sets. Some standard splits are (train/validation/test) 60/20/20 or 80/10/10. The more data you have collected, the smaller you can make your validation and test set target size.
To distribute the data into the three sets, follow the steps:
-
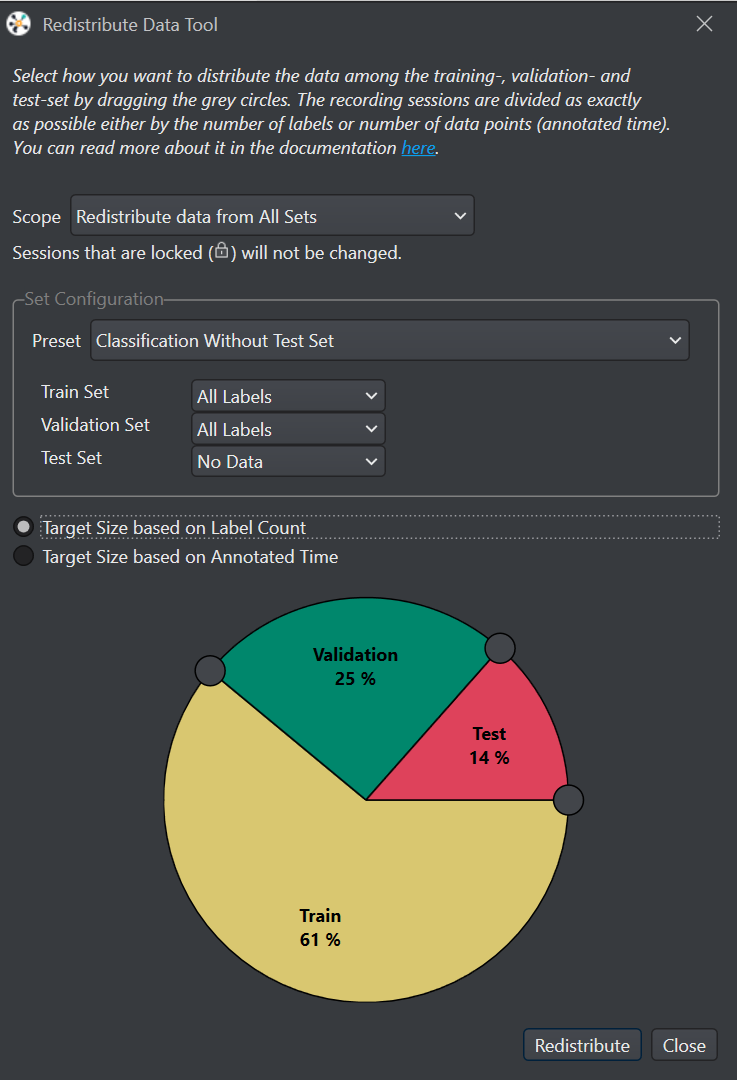
Open the project file and select Redistribute Sets. The redistribute data tool window appears.
-
Set Scope as either Redistribute data from All Sets or Redistribute data from Unassigned sets.
-
Use the graphical tool to distribute the data into different datasets. The target size can either be based on Label Count or Annotated Time.
-
Select Redistribute and the data in the selected scope will be distributed among the three data sets.