Release Notes 5.11
This section lists the new functionality, improvements and some of the major changes related to DEEPCRAFT™ Model Converter.
New Features and Enhancements
Use Imagimob API or Ml-middleware API for Code Generation
When generating code with Model Converter, you can select either Imagimob API or ml-middleware API as the target API. Depending on the selected API, Model Converter generates different levels of integration code for your application.
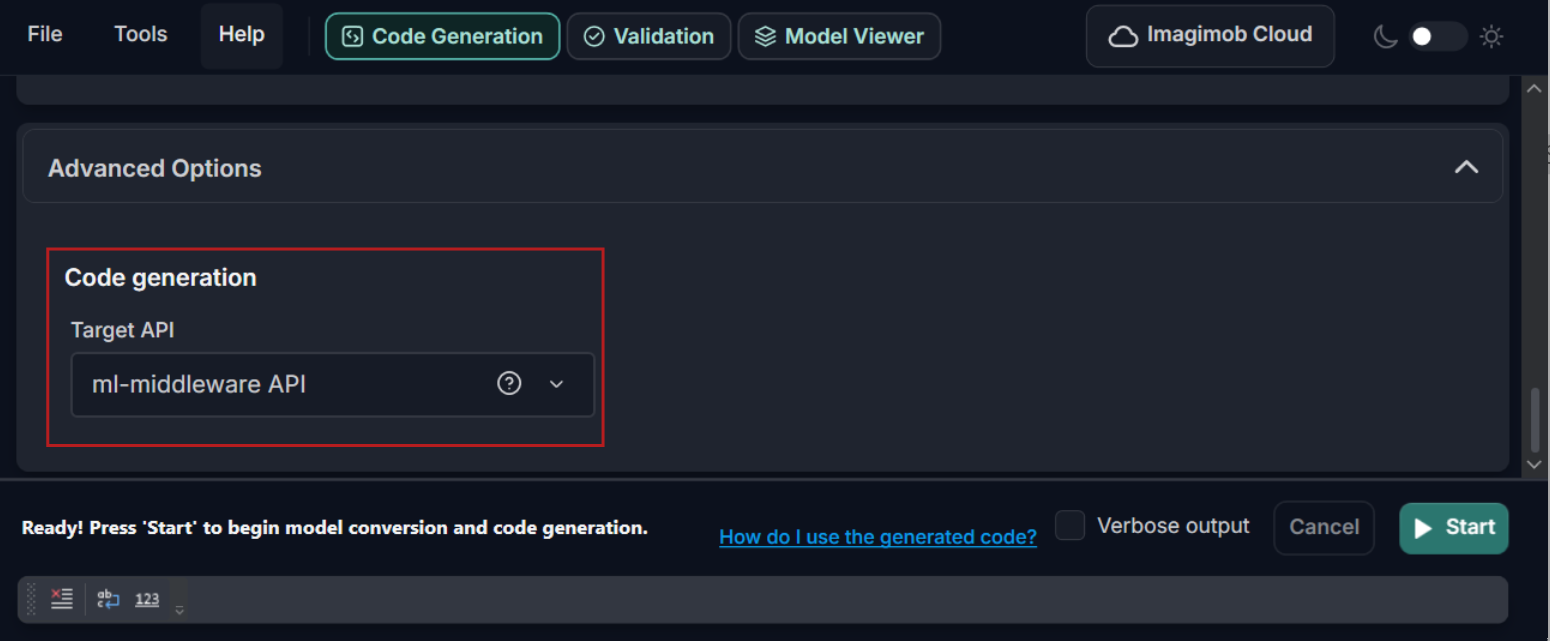
Select Imagimob API for a ready-to-use wrapper that generates model.c and model.h with the ‘IMAI_*’ API. Select ml-middleware API when you want to integrate the generated model artifacts directly through Infineon’s mtb_ml_* API in your ModusToolbox™ application. Refer to Deployment API to know more.
Refer to Target API in Graphical User Interface and Command Line Interface sections for more details.
Set the Memory Placement options for the Imagimob API
Added support for configuring memory placement when generating code with the Imagimob API. You can now choose the allocation strategy for the tensor arena, used as model working memory, and select where the model weights are stored at runtime. Arena allocation supports static global buffers or dynamic heap allocation, while weights can be placed in flash, static memory, or dynamically copied to RAM during IMAI_init().
The Memory Placement options are available only when the Target API is set to Imagimob API.
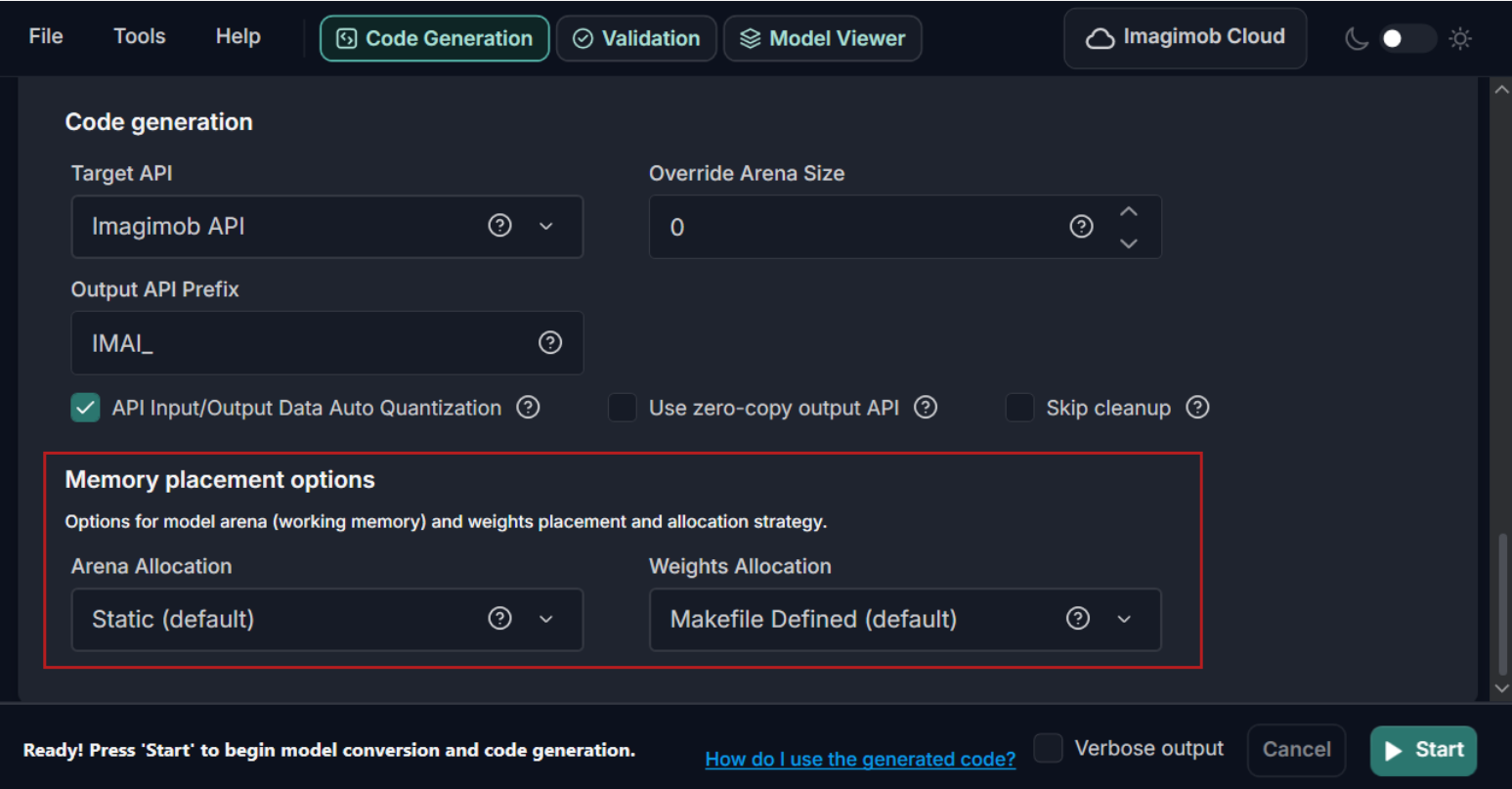
Refer to Memory Placement options for the Imagimob API in Graphical User Interface and Command Line Interface to know more.
Multiple Input and Output Model support for PyTorch (.pt2)
- Generate code for models with multiple inputs and outputs.
- Use the NPZ data format for multiple-input and multiple-output models.
- Deploy multiple-input and multiple-output models without modifying the original model architecture.
Added Ethos-U55 NPU optimization options for PSOC™ Edge M55+U55
Two new optimization options are now available for PSOC™ Edge M55+U55 in the Code Generation tab: Arena Cache Strategy and Force Python Backend.
Arena Cache Strategy allows you to choose how the arena cache size is determined for Ethos-U55 NPU memory optimization. You can select Min, Max, or Custom. Max is the default option, while Custom enables the Arena Cache Size field, allowing you to specify the cache size manually in bytes.
Force Python Backend enables the deprecated Vela Python API backend for model optimization when required. When enabled, additional Python-backend-specific settings become available, including Recursion Limit for large model graph traversal and Max Block Dependency for controlling dependency delays between NPU kernel operations.
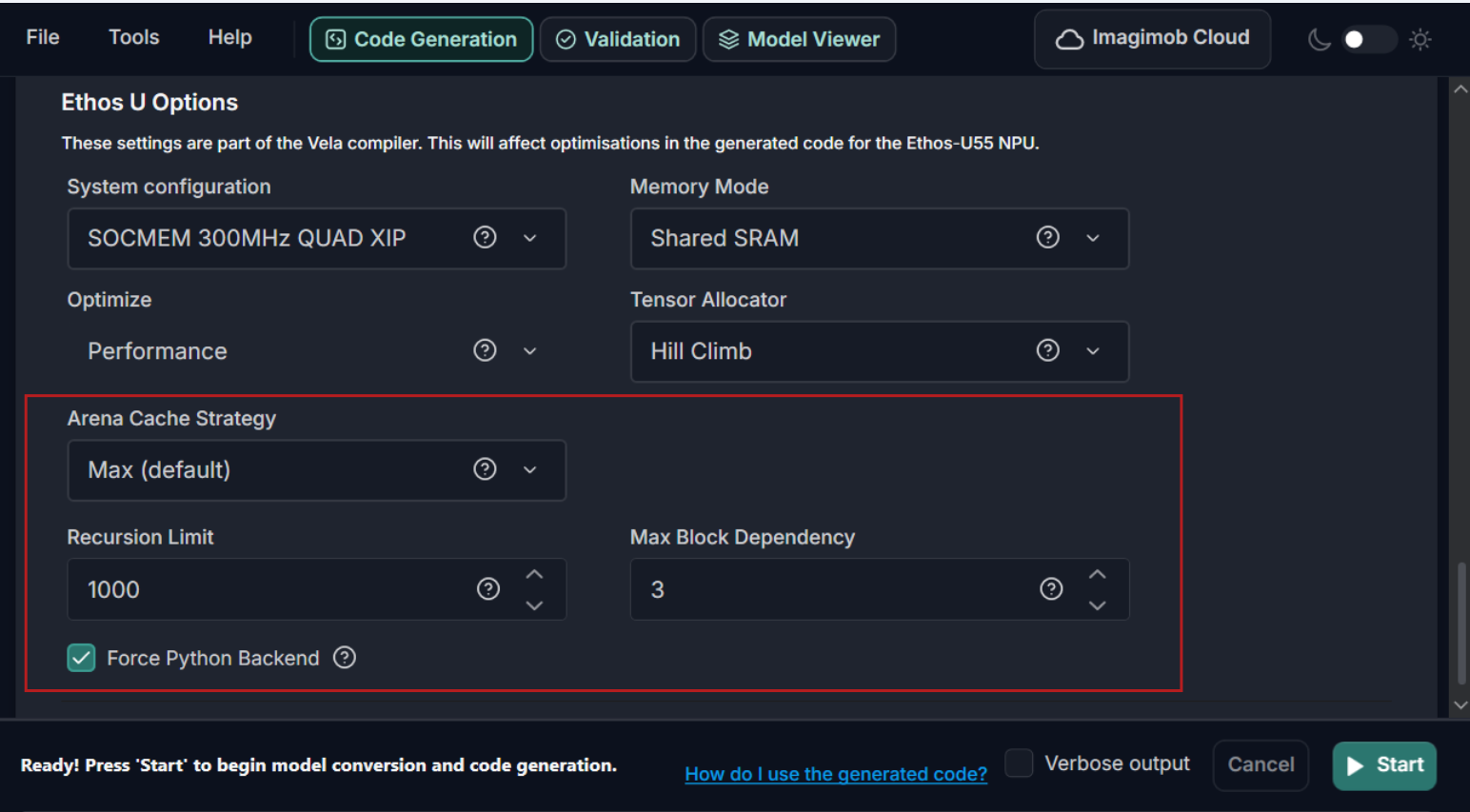
Refer to Advanced optimization for PSOC™ Edge M55+U55 in Graphical User Interface and Command Line Interface to know more.
Fixes
- Other small bug fixes and improvements