Supported Data Formats
This section outlines the supported input data formats, structural requirements, and the expectations for data shapes and values.
General Expectations
- Numeric dtype: Features and outputs are read as
float32. - Batching/Shape: Features must match the expected input and output shapes, including the batch dimension.
- Headers: CSV files may include an optional header row. If the first line contains letters (excluding the letter ‘e’ in scientific notation), the header is detected and skipped automatically.
Supported input types
- NPZ file with arrays
- CSV file(s)
- Recursive folder and dictionary file (mix CSV samples and JPEG images)
For models with multiple inputs and outputs, use Compressed NumPy (.npz) only, as no other data sources are supported.
NPZ (NumPy compressed)
Below are the NPZ file format specifications for single-input/single-output and multi-input/multi-output models.
Single-input/single-output models
For single-input/single-output models, the NPZ file must store the input as the first array and the output as the second array. A single .npz file can contain one or two arrays:
Inputs:
- Preferred keys:
input,x,X,features, orarr_0. - If none of the preferred keys are present, the first array is used as inputs.
Outputs (paired):
- Preferred keys:
output,y,Y,labels, orarr_1. - If none of the preferred keys are present, the second array is used if available.
Requirements:
- Inputs are converted to
float32 - For paired data, outputs must be present and re-shapeable to the specified output shape
np.savez("data.npz", x_data, y_data)Multi-input/multi-output models
For multi-input and multi-output models, name the arrays in the NPZ file to match the model’s input and output tensor names. Use a tool such as Netron to inspect the tensor names and ordering in the model file.
Some .tflite models use verbose tensor names, such as serving_default_input:1:0 for inputs and StatefulPartitionedCall_1:1 for outputs. For these models, name the arrays in the NPZ file as "input_0", "input_1", "output_0", "output_1", following the exact input/output order shown in Netron’s Graph Properties panel. The array names do not need to match the names shown in the graph view; only the tensor order matters. See the image below for an example.
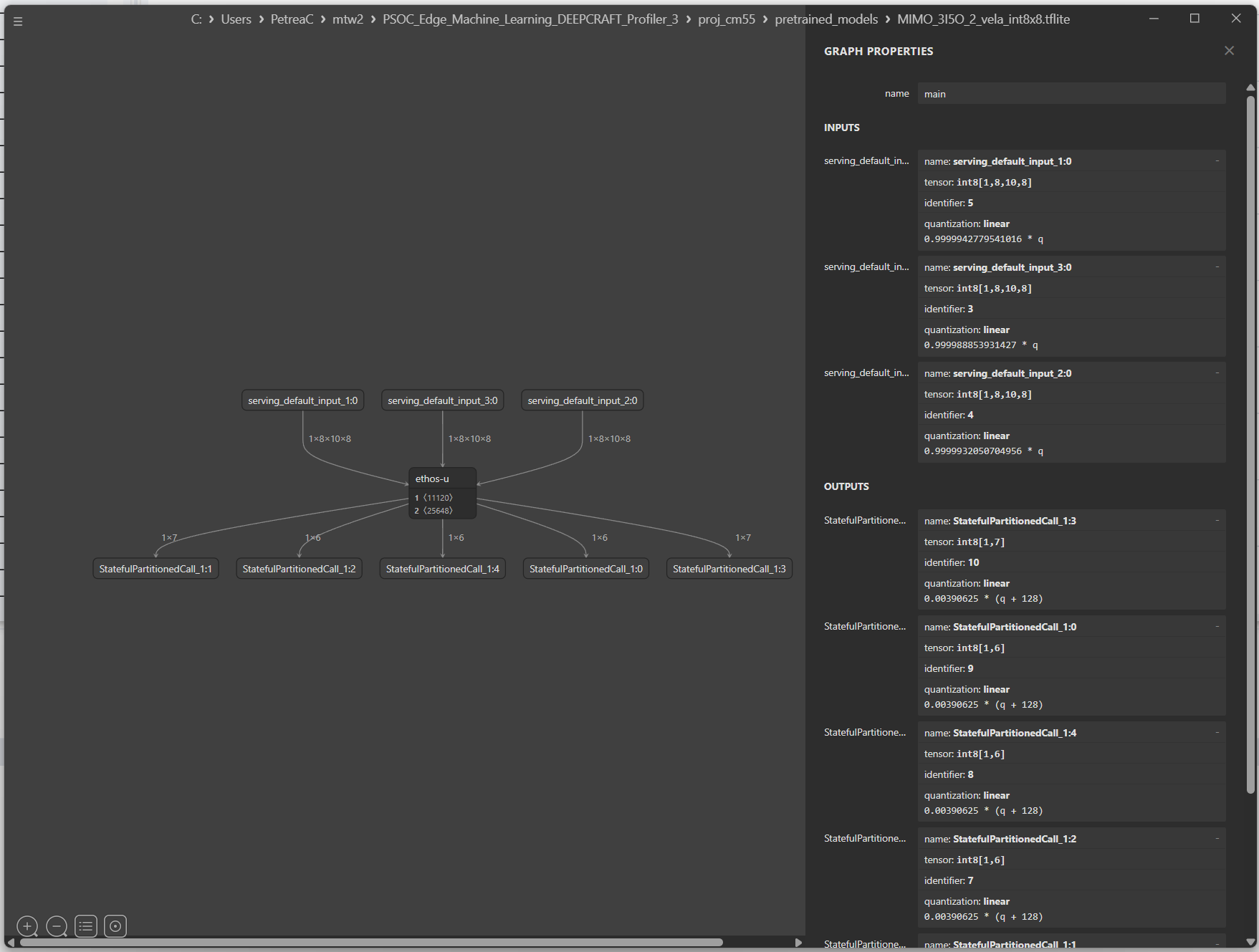
Below is an example of how to save an npz file with 2 input arrays and 1 output array:
# Example: saving data for a model with two inputs named "encoder_input0" and "encoder_input1" and one output "encode_output"
np.savez("data.npz", encoder_input0=x0, encoder_input1=x1, encoder_output=y0)CSV Inputs
CSV data can be provided in multiple layouts. All numeric values are read as float32. Each row represents a sample with flattened input data (optionally including flattened output data). All data are read as flattened arrays and reshaped to the target dimensions.
- Optional header row is supported
- Input columns: 0 to (input_shape_product - 1)
- Output columns (if paired): from input_shape_product onwards.
- Shape after load and reshape:
[num_samples, ...input_shape_dimensions].
Example:
Two samples, three features:
f0,f1,f2
0.1,0.2,0.3
0.4,0.5,0.6With embedded labels (two samples, three features, one prediction):
f0,f1,f2,label
0.1,0.2,0.3,1.0
0.4,0.5,0.6,0.0Recursive folder with dictionary
Use this option to combine CSV samples and JPEG images from a base folder, with per-sample outputs specified next to the paths. The dictionary must be a CSV-formatted file saved with the “.txt” extension, all paths to the sample files are relative to the dictionary file.
Base folder and allowed file types
- Base: Root of the dataset folder tree
- Allowed file types:
- CSV files: Must represent a single sample per file (exactly one row)
- JPEG images: Only
.jpegfiles are supported
- Not supported: NPY and other image types (e.g.,
.jpg,.png)
Dictionary file format:
- CSV-formatted text file use to enumerate samples and outputs.
- Ignore empty lines and lines starting with
# - Each non-empty and non-commented line:
- First field: path relative to the base folder (no absolute paths; must not escape the base).
- Remaining fields: numeric output values (if outputs are used).
- The file is always parsed as comma-delimited with optional spaces after commas.
Examples: Input-only (no outputs):
data/sample_01.csv
images/img_0001.jpegPaired (outputs after the path):
data/sample_02.csv, 0.0
images/img_0002.jpeg, 1.0, 0.2, 0.3Sample constraints
- CSV entries: Each referenced CSV file must contain exactly one row.
- JPEG entries:
- Images are resized to the target resolution and channel count:
- If channels = 1, converted to grayscale; otherwise converted to RGB (3 channels)
- Pixel values are normalized to [0, 1]
- Shape of each image sample before batching:
[height, width, channels]
- Images are resized to the target resolution and channel count:
Outputs in dictionary rows
- If outputs are used, the values following the path must be numeric (floats).
- For multi-dimensional outputs, provide flattened values in row-major order
- Total count must match the product of the expected output shape
Shapes and Validation
- Feature shapes:
- Flattened CSV:
[N, flattened_input_size]reshaped to[N] + input_shape_dims. - JPEG (folder with dictionary):
[N, H, W, C].
- Flattened CSV:
- Output shapes (paired): reference outputs must be reshapeable to
[N] + output_shape. - Dtypes: All inputs and outputs are processed as
float32.
Quick checklist
- Headers in CSVs: If a header is present, it is detected and skipped automatically.
- Single-row CSVs in dictionary mode: CSV files referenced by the dictionary must contain exactly one row (one sample).
- JPEG-only for images: Only
.jpegfiles are supported for images in recursive folder mode. - Relative paths in dictionary: Paths must be relative to the base folder and must not escape it (no
..traversal and no absolute paths).